Unsupervised State Representation Learning in Atari
[Paper] [Code]Journal: NeurIPSYear: 2019Institute: Mila, Université de MontréaAuthor:Ankesh Anand*, Evan Racah*, Sherjil Ozair*#State Representation Learning #Constrastive Self-Supervised Learning
State representation learning without supervision from rewards is a challenging open problem. This paper proposes a new contrastive state representation learning method called Spatiotemporal DeepInfomax (ST-DIM) that leverages recent advances in self-supervision and learns state representations by maximizing the mutual information across spatially and temporally distinct features of a neural encoder of the observations.
0.Mutual Information
- What is mutual information?
Wikipedia-Mutual information It quantifies the “amount of information” (in units such as shannons, commonly called bits) obtained about one random variable through observing the other random variable. - Why to maximize it?
1.Spatiotemporal Deep Infomax
Prior work in neuroscience has suggested that the brain maximizes predictive information at an abstract level to avoid sensory overload. Thus our representation learning approach relies on maximizing an estimate based on a lower bound on the mutual information over consecutive observations $x_t$ and $x_{t+1}$.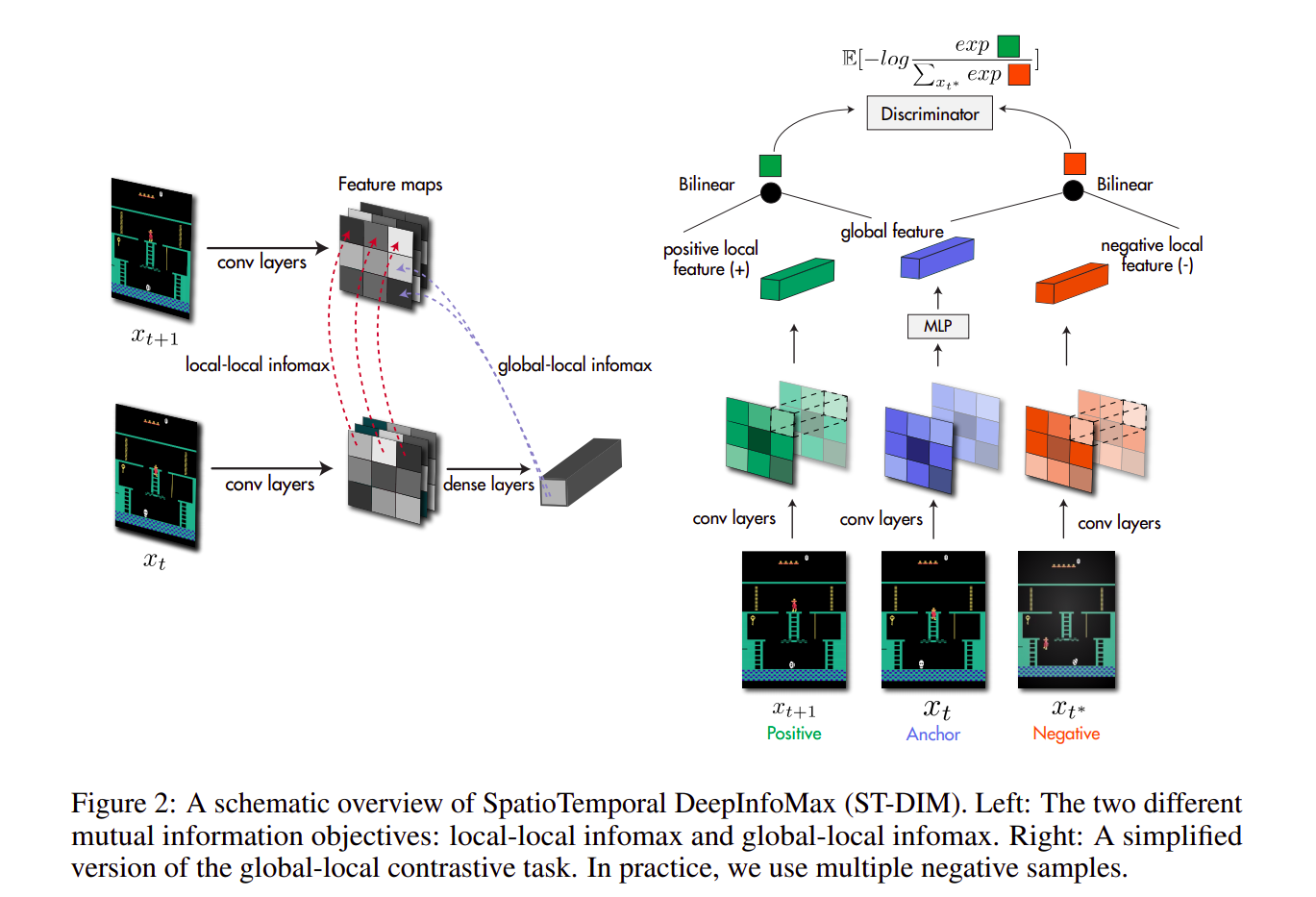
For the mutual information estimator, we use infoNCE:
The global-local objective(The representations of the small image patches are taken to be the hidden activations of the convolutional encoder applied to the full observation):
The local-local objective:
2.What the constrastive task is.
I’ve ask a question about this paper, and surprisingly the author Ankesh Anand himself answered my question. He said:
It’s easier to think of the method in terms of what the contrastive task it than to understand the mutual information stuff. The contrastive task is: Correctly classify whether a pair of frames are consecutive or not. To do this task well, an encoder needs to only focus on things that are changing across time (often there are high-level features such as the agents, enemies, scores etc.), and ignore the low-level or pixel-level details such as the precise texture of the background. For solving the contrastive task, we use the infoNCE loss. Turns out if you minimize the InfoNCE loss, it is equivalent to maximizing a lower bound on the mutual information between consecutive frames.
If you do this classification task between whole frames, the encoder will focus only on high entropy features such as the clock since its changing every frame. So, to prevent the encoder from focusing only on a single high entropy feature, we do the contrastive task across each local patch in the feature map.
3.Framework
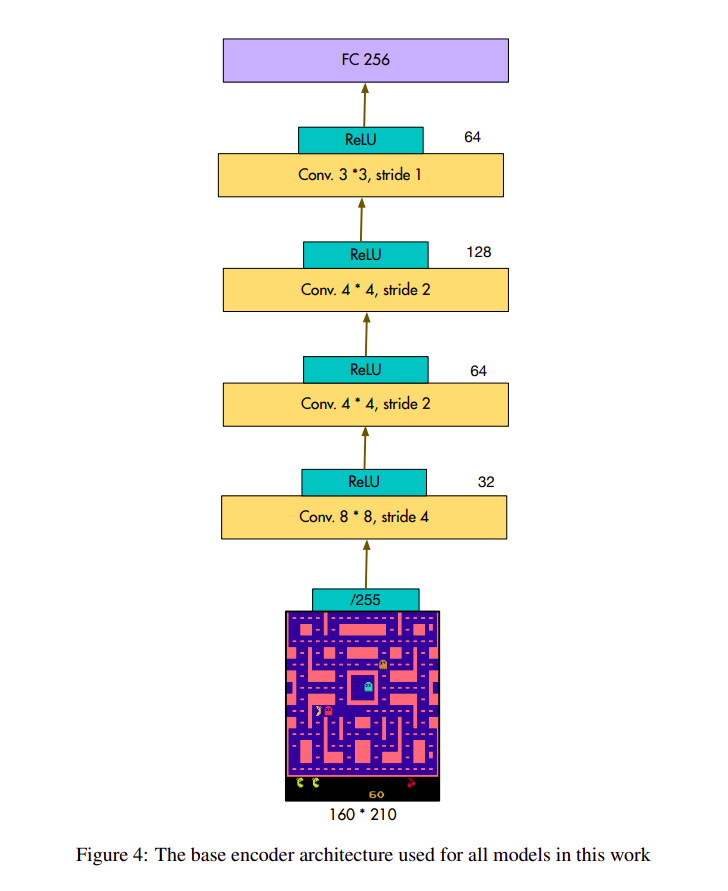
4.Discussion
We also observe that the best generative model (PIXEL-PRED) does not suffer from this problem.It performs its worst on high-entropy features such as the clock and player score (where ST-DIM excels), and does slightly better than ST-DIM on low-entropy features which have a large contribution in the pixel space such as player and enemy locations. This sheds light on the qualitative difference between contrastive and generative methods: contrastive methods prefer capturing high-entropy features (irrespective of contribution to pixel space) while generative methods do not, and generative methods prefer capturing large objects which have low entropy. This complementary nature suggests hybrid models as an exciting direction of future work.